- A Landscape of Opportunities
- The Cost of Redundancy
- The Logic Paradox
- Mind Abstractions of Endpoints
- (API) Gateway to … Something
- Designing the EntryPoint API
- Giving Name to Your Logic Spaces
- Entering SST, the Single Source of Truth
- Embracing Community to the Core
- Wait, Did You Forget the Backend?
- Almost a Conclusion
- About the author of this document
Abstract
The current software compliance landscape relies strongly on de-facto SBOM standards as the correct relevant documents to attest to all the end needs. One consistent issue in the generation of these documents is the data gathering among multiple sources of information, as none of the tools provide everything, the so-called magic silver bullet.
As a solution, a central placement of unique data shared by all tooling would be ideal, but achieving this with multiple tools that do not communicate with each other is highly unlikely an easily solvable task.
The idea of abstracting the SST ( Single Source of Truth ) is to provide a stable contractual interface where the data connection between tooling and storage could be decoupled and used with the discretion of developers and companies’ choice, preventing polarization and hurdles on the platform engineering architecture.
A Landscape of Opportunities
Since the conception of the Open Source Tooling Group 1, the work to create as most as possible a well-defined open source compliance tooling landscape has been performed in incremental steps.
Two singular characteristics were relevant to this work. Compliance software was not a regular attractive open source projects for a general audience and was mainly business oriented.
That turned the development approach driven mainly by companies, making individual attempts to fulfill the entire landscape. The group divided efforts into pinpointed areas that could quickly satisfy the landscape, which proved efficient, but development started for each application in a silo where no data exchange was planned.
But one common topic floated in every significant discussion, though, data exchange.
Despite that, it never reached the ideal solution, as the tooling landscape itself were still in the infancy of development and work was primarily distributed and disconnected. Some of then not even been open sourced yet.
Companies that began introducing compliance landscape work internally started to create a considerable amount of work to do the data exchange process, sometimes creating extra internal tooling and sometimes adding extended functionality for their primary tooling. Modern CI/CD techniques were yet to be pervasive, and API’s backends were in their inception stages.
Coming up for recent times, software compliance and vulnerability analysis growth exponentially, the number of tools and approaches multiplied, and CI/CD has become the norm, not the exception, making data exchange essential. Standards for Software Bill of Materials, known as SBOM, became effective through SPDX2 and CycloneDX3, and standard license definitions became a central pillar of the process even so their been a file format exchange, so not suited for large scale operation.
And as most open source projects, even primarily company-backed for compliance software, the resources to develop everything inside each application became very scarce, not to mention redundant work that could be applied differently.
The fundamental concept of this paper is to provide this possible approach to tackle the data exchange for tooling in an incremental process allowing tools to evolve to use the model.
The Cost of Redundancy
As stated before, the tooling landscape evolved so that every tool needs to perform some extended functionality not intended as their core concept. This process adds indirect costs of architecture, development, maintenance, and extending the data model to accommodate the needs. And, of course, this not stops here.
Adding up the difficulty to acquire new contributors due to inherent business-oriented software, i.e., non-attractive to the general development community, it turns out to be a costly development and, most of all, slow improvement cycles due to diverting the limited resources to fill non-essential core features.
To exemplify this behavior, let’s present the first scenario on how three of the most common open source compliance tools deal with SBOM generation from the same source code.
- ORT4, a compliance and vulnerability analyzer and process orchestrator
- ScanCode Toolkit5, a widely used compliance scanner
- SW3606, a component and project software inventory and catalog.
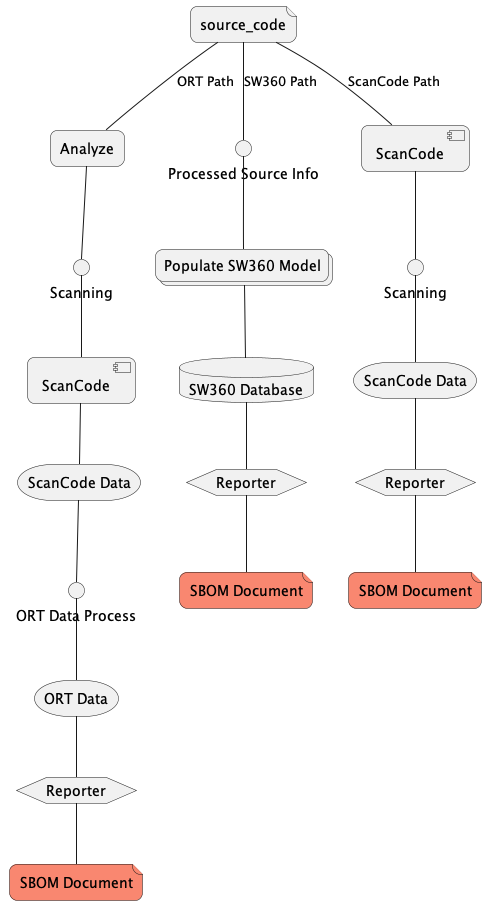
Three different tools, each one with its model and with two things in common, the source code origin and the SPDX7 document generated. Each produced a set of processed data from the source code in multiple steps.
Scancode8 scan license, copyrights, and vulnerability from the source and has an internal reporter for creating documents formatted to SPDX9 in the multiple possible accepted formats defined by the specification.
Ort[“fn4] does in-depth software analysis, even using ScanCode10 as one of the possible scanners, to generate their model metadata. It has an internal reporter to generate SPDX11 documents like ScanCode12, but then with different data.
SW36013 process inputted data ( manually or through Rest API ) and create an internal model which is Document oriented, and then, again, have an inner reporter to generate the SPDX14 document with different data.
There’s no guarantee that the required minimum data from SPDX15 specification in the documents will be precisely the same. And the source of origin still is the same.
In an E2E scenario, all the tool outputs are required. In the typical case, it pushed developers to create mechanisms to gather these multiple sources of information to attempt to create a sensible merged set of data, which would become the final document from the source of origin.
The outcome of this scenario is an increasing amount of the cost of development at any point of the development pipeline:
- Open source projects need to create, maintain and rewrite the generators for each new SPDX16 specification, most of the time reaching the limitation of resources.
- CI/CD complexity increases to manage multiple inbounds and outbounds documents generated by multiple sources.
- End customers need to create parsers for each document generated to get the desired outcome, increasing the cost and adding extra development work. Cost itself can increase tenfold, considering that the assigned development team must understand multiple software architectures and their data models.
The second scenario exemplifies exact these last outcomes.
With no exception, every single compliance tool relies on a conformant License database or list. The most commonly used sets are SPDX License List, which provides multiple formats in human and machine-readable ways and Open Source Automation Development Lab (OSADL)17 license checklists in raw data form
Both license lists provide multiple formats as human readable or programmatically form and are in a different format than what is accepted by the tools above. Each tool has its way of using this dataset, forcing it to do a particular conversion to adapt.
For this case, a third-party application was born called LDBcollector18, which does a complex process of merging a selected set of input license lists and generating formatted output for multiple targets.
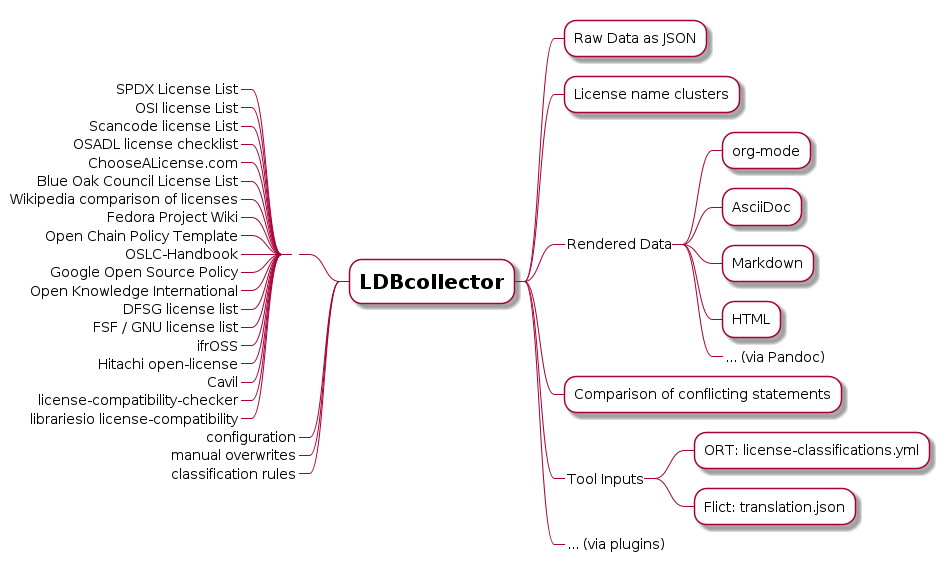 Credits: LDBcollector authors
Credits: LDBcollector authors
If a common central dataset in a well-defined process to acquire it exists, the need for such technical and complex software would not be needed. It would cause a reduced time of development, integration, and many of the processes that would be causality to properly work and keep in sync with every update from the original license lists.
The Logic Paradox
So, as presented, the issue exists, and no party could be blamed for that, as the natural evolution of compliance software development happened. The next evolutionary solution was logic, a central database or object storage. To simplify the solution, let’s stick to the database.
In the first step, we will make a central database that provides the data for the tools. Using the same tools presented before would be something like this:

Solved right? All tools use the same dataset stored in the database and share their content, so there is no duplication, and everyone can generate their documents.
Let’s extend this because the problem still needs to be solved, and even so, I will explain how this creates another bigger problem to solve.
We moved the architecture further to attempt to solve our original single problem. We want to solve the end of document generation in a way that we get rid of redundancy on some of the software capabilities on the tools.
Let’s see what we can do with a simple extension:

Solved right? Now we are all happy with doing what our tools suppose to do best and the task of creating a fantastic well-formed layout document for managers and legal teams. We are all happy and go ahead with green pasture. Is it so?
Now we have two more extensive issues. Solving the main one created a tiny monster in our hands.
Before a proper set of explanations, see the following graphic:

Did you see what happened ?
So, two major problems exploded in the hands of developers now, and the attempt of harmonize the tooling landscape, we added complexity.
Let’s start with the simplest of the two problems, functionality. In order to not loose the original functionality, generate a report, all tools need to create another way to connect to the new reporter to request an output, and even worst, unless a well formed interfacte contract is done with longevity stability guarantees, will be a complete cat and mouse game. I do not need mention how costly is the game of catching up in software development.
Yes, this is the small problem of the two.
The big one, and the reason i called a logic paradox, is that centralizing on the database to simplify data access, we increased the cost on changing the model architecture and direct access to it. And years of development of all tooling create large code bases and not one or two, but multiple languages.
Then what happens ?
- If considered to go ahead, months of discussions between multple different development teams, software architects on how the access would be, lots of diagrams.
- Add multiple months to say what is the perfect database or storage backend. And companies behind would add their weight to orient the choice.
- Months lost to development of the tools in the search of a unicorn that make it better, or the standard that will became defacto the one 19
- Indirect pressure coming from different actors trying to provide the silver bullet ( that not exists )
Reality ?
- Lost time to design, and no one will adopt because let’s face it, developers and architects are ( agree or not ) humans, and agreement is hard. And time IS money.
Mind Abstractions of Endpoints
Following this document, the traditional logic solution for software architecture will not work.
- Tools can not simply stop current development and maintenance and spend time to do the changes needed
- Resources are limited, especially in the space of open source development
- There are different agendas for the possible customers of this work
- Silver bullet is a myth
But what if we look at non-traditional ways? In recent years, we had an explosion of web development techniques for application development, and a unique result of all this was the vast development of APIs
Application Programming Interfaces existed as long as we can remember, is nothing new, but Web development brought in a different context. They started to use it to facilitate access to an application through the internet, been early browser requests to modern, sophisticated router systems.
It brings us an interesting side effect, and we need some mind abstraction to see it.
What if these sophisticated API routing systems could become a bridge for data exchange?
And what if this provides a rigid API contract decoupled to access data without forcing extreme software changes and allowing the possibility to choose storage and backend?
At this moment, I can see you yelling. It’s an API, nothing new. Yes, it is an API but it does not solve the goal. It is just the start of the possible solution.
(API) Gateway to … Something
One modern approach becoming pervasive nowadays is API Gateways20 21. And from the point of view of a platform engineering architecture, it would be the first choice as a Swiss knife regarding operations.
API Gateways can be entry points with authentication, throttling, cache, and even data transformation, hinting at the solution.
If we want to centralize the data in a common endpoint, we must do data transformations if the gateway is the target.
But then, things are complex, as one of the requirements to have an API gateway work for you is that both sides of the transaction have their APIs well formed, which is far from the reality of existing tooling now.
Few rare cases have rest APIs defined; in most cases, they are limited to a minimal functionality deemed necessary. Remember, most of these applications were born with a different usage target when distributed data exchange was complex and costly.
Using an API gateway would indirectly force application developers to add a layer with a committed contract of stability to their applications. At the same time, the backend needs to be developed with a rigorous interface that most application developers need to agree on.
For example, it matters if the main application tries to update user information with some parameters and the backend expects other income. Some data will be loose.
Still, there is work on the compliance landscape presenting only one possible approach with API gateways. Mentioning two specific cases, nexB VulnerableCode22 and purldb23, are great examples where detailed data have their API interface contract well formed. So, as standalone applications, they provide a specific API for one component of the compliance and security landscape. And this could be how an API gateway would be a perfect solution. But then, we would need to create one service per need, which would generate a higher cost of development and time, and again we round back to the same issues above. But do not relegate these two cases. We will revisit them later since a vital part of them is another piece of the solution puzzle.
Unfortunately, even with API gateways being helpful, in this case, if we do not have a well-defined API that is visible front and not behind a gateway, this is a lost cause. We are almost exhausting our alternatives.
Designing the EntryPoint API
API gateways are not the solution but hint at what is needed. Here is a quick recap of the general requirements gathered during this analysis:
- Applications need access to the same central data source
- Applications will not change their internal architecture
- Applications need to keep all their current capabilities, at least until the central data source is stable
- The technology used by the model should be open to choice as long the interface is defined
Using the same tool actors before in this document, what could be this scenario and using two simple operation calls?

We now reach a point where tools can use the same dataset to get and add components and licenses. What changed now is that we can introduce the same Super Report Generator without changing the functionality of the applications, and applications can add access to the API gradually.
The effort to change the application’s code will be less than previous iterations, as we kept the original architecture and language and were not forced to introduce a direct connection to the data source, but in a frontend, API as a rigid model.
Now we have some abstraction and can fit into the requirements set. And this will generate another set of functionality requirements now. As soon the logic model is defined, some joint operations will rise, which then would be added to the API.
Let’s say that some tools need all components with the license xyz. We obviously will add one endpoint and be done:

There we go. We have the new endpoint. Easy but dangerous, we mix concepts on the API model and create a precedent. Not only do we incur the risk of overpopulating the API, but we also have a likely chance of loose control of relevancy and the proper contractual base interface expected. These can be solved in a proper direction, using logic separation, even to treat the specific corner cases that application developers would bring.
Giving Name to Your Logic Spaces
Namespaces, simple as usual, can resolve the situation of overpopulation as long we limit the depth we go.
The logic applied to compliance models should be oriented to functional than operational logic. In a way, the core API model, which we start to call from now SST, should be treated in two blocks:
- CORE endpoints
- UTILITY endpoints
Core endpoints
In a simple explanation, CORE endpoints is the ones that execute 1x1 operations directly with the core compliance objects.
These would translate directly to the specification core elements, like Document, Package, License, Project, and so on. Operations over core entities should be sufficient and simple, limited to core data only, and 1x1 representations, i.e., add a new license.
Utility endpoints
Utility endpoints act over several core elements and do not depend on a single entry point to work, i.e., get_components_with_license will react over both package and license data to return a functional result the query.
Lets’s modify the current implementation to accommodate the namespace idea.

See what has been done? Separating direct and functional operations, we now create a clear path to understand what is going to where. But still not there yet. Two important focused points are missing here, the what part, on what should go to core and utility operations, and the how we will execute corner cases, or better phrased, entire operations that will use elements or core API, but are somehow dedicated only to a single or few tools that operate over the central model.
Entering SST, the Single Source of Truth
Design the SST API model, if departed from ground zero would be a difficult process. The intention to centralize a model were neve to create a new standard, which will be ended in a position to be just another attempt that, unless a lucky shot, deat in the water. It should be rooted in some already proved pilars of software compliance.
Without this, create the base core and utility endpoints easily would result in insufferable discussions.
So, it need to be rooted.
SST API Model should have one big requirement:
- Provide all elements necessary to an application generate a conformant SBOM
And for that, there are two specifications that should be adopted, SPDX24 and CycloneDX25.
So, with this in mind, we reduce or efforts on create the base endpoints, we folow the SBOM both specifications and depart from a solid proved basis. The specifications will provide the template on what information we should and must update and retrieve data from the central backend. This would be the definition that goes to core SST endpoins
For utility endpoints, this will be created based on current common tooling requests, and mostly will need to be identified during the development process by a community shared work from all tool developers. Is clearly the most difficult part, as any possible utility opration will come to mind, and large part, an specific utility entry would be requested and clearly not be part of utility from base. That’s why we started from namespaces
Namespaces: We came in (Extented) Peace
The whole setup of the SST API model was done in a way to accomodate Dynamic namespaced endppints. The whole idea behind this would be allow specific tools add their own core and utility endpoints, without touch the base.
And not only that, as noted, we not have a rigid implementation behind the API model, neither a rigid storage backend, meaning, we’re open even to additinal entries as a company namespaces, which would create an entry on the API model for their specific needs, without interfere or require modificationon the base SST.
We reserve the second level namespaces code and utility for specisal cases, and exclusive functionality got to the root to the extension.
Let’s play with our diagram again. The SW360 tool need a utility function that will request a product owner of the package, really dedicated to the nature of that software and add a core functionalioty that expects be exclusive, direct project access. And at same time the_company will need to add a utility function to request all all packages with license SOME and see any bugs in their ticket_system.
How the scenario changed ?

Since the backend development is hidden behind the API, it allows any external actor to add their exclusive functionality, not affecting the main contact API, increasing the attraction to use a central data source for almost everything.
One interesting point to notice in the example above is the usage of the core namespace for the specific software. These can signalize a candidate for the following API revision to upgrade to the base.
During the new version model specification, a proposal from software team development to raise their core and utility levels could be an indication.
And using the original example of redundancy, how the scenerio would be?

Embracing Community to the Core
One of the most complex tasks in implementing the SST API model will be to decide on the core endpoints. Gladly, we are not alone, and we circle back to this document’s start. It’s been years since brilliant developers thought in many of these aspects.
An excellent example of which endpoints we can reference or even translate 1x1 is what I mentioned before on nexB26 tools, like purlDB27, which defined the template of several of the core entry points we would require on SST.
Governance software like FOSSlight 28 and SW360 29 provides enough logical information for core components surpassing SBOM limitations, like project information.
These can be taken with a grain of salt to how an approach to this information gathering need to be done, as clearly all the parts that originated the ideas should be considered active participants and have a good voice in the design, as they are the first target audience.
Wait, Did You Forget the Backend?
No, of course not, but this white paper’s main target was attempting to abstract the storage. We have even gone further and are attempting to abstract the API implementations.
During the research for this paper, a common subject was always present, independent of the source you talked about: Why not use < place here something >? Attempting to control the preferences of developers or even trying to control how an enterprise environment should use their data is proven inefficient and improbable. The researcher itself confronted a situation where he had the final say on the backend decision. Still, a platform engineer in charge repeats the same question in every meeting simply because of their preferences.
The situation replicates itself when talking about the API implementation. We could offer the ideal implementation, but we always face problems like an entire team is used to working in a different environment than the suggested implementation. They obviously would prefer to work on their implementation since they know better. Again, in this case, it is human nature added to the time and costs involved.
Since the origin of this research, the attempt would be to refrain from interfering ( too much ) on left and right, or better said, the applications and the backend storage decisions.
Executed right can be future-proof as all parts can be transitional. The entire set of applications can change as long the interface is stable. The whole storage and API implementation can change as long as the interface is stable.
We implement a model, a rigid contract interface between the data and the applications. The other parts are in the hands of those who know better what to do, how, and where to do it.
These do not exempt the necessity of one thing: A reference implementation need to exist. As long as the project reaches the stage of implementation, we will need to create a formal open source reference implementation but treated as independent of the SST API model design.
Almost a Conclusion
This R&D paper is far from being finished, but it put in place one idea that has been breeding for several years. The first intention was open up to all intelligent eyes and years on the several practices involved in this paper, platform engineers, API developers, and tooling developers to improve and point out possible flaws and improvements.
That’s Open Source for you.
About the author of this document
Despite been write by a single hand, this document was drafted with hundreds of ideas and observations on all open source circles and companies. Hence, the credit goes to the open source community spearheading world innovation for some time.
My sincere thanks for all the work everyone is doing.
Central
Abstraction Model as a Single Source of Truth for Compliance and
Vulnerability Software with Open Source Approach by
Helio
Chissini de Castro is licensed under
CC
BY-SA
4.0![]()
![]()
![]()